LLM Wiki for Business Owners: What Karpathy's Pattern Means for Your Business
Every time you open a new Claude or ChatGPT session, you brief it from scratch. You paste in context. You re-explain what the business does, who the client is, what decision you made three months ago. The AI answers your question, and the answer disappears when you close the tab. Nothing compounds. Nothing builds. Your business knowledge still lives in your head, and every session starts from zero.
This is not a personal productivity problem. It is an architectural one. The entire first wave of "AI for business" was built on retrieval: find the relevant chunk and answer the question. RAG (Retrieval Augmented Generation) looks smart in demos. It collapses on the nuanced questions that actually matter, the ones that require synthesizing everything your business has learned over time.
The LLM Wiki is a knowledge architecture pattern by Andrej Karpathy where an AI agent synthesizes documents into structured, interlinked pages at the moment of ingestion. For businesses, it replaces stateless document uploads with a compounding knowledge base. Every meeting transcript, client note, and decision gets organized so AI agents can reason from it immediately, not re-discover it from raw files.
This is what that pattern means for service business owners, and why the business angle is the one story nobody has told yet.
What Did Karpathy Actually Publish, and Why Did It Spread So Fast?
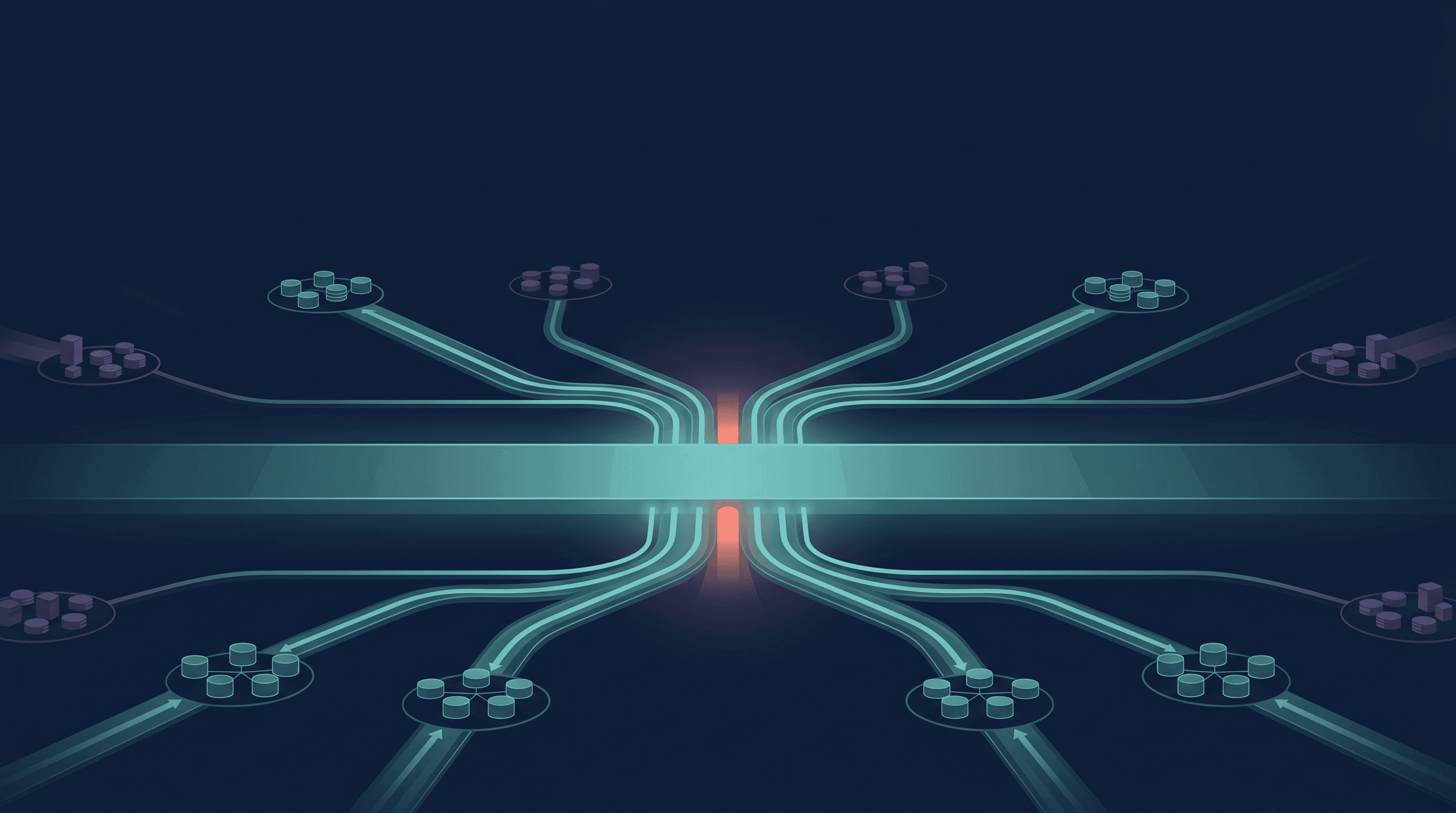
On April 4, 2026, Karpathy posted a GitHub gist called "LLM Wiki". It describes a self-maintaining knowledge base where an AI agent synthesizes every new document at ingestion rather than storing raw text for later retrieval. Three layers: raw sources, a wiki of synthesized pages, and a schema that tells the AI how the wiki is organized.
Within days it had 296 HackerNews points. Within weeks: 5,000+ GitHub stars and over 100,000 bookmarks on X. Garry Tan's GBrain implementation hit 13,800+ stars. Developers were building versions in Python, TypeScript, Go. Ten-plus open-source implementations appeared in the first month.
Why it spread so fast: Karpathy co-founded OpenAI in 2015 and directed AI and Autopilot Vision at Tesla from 2017 to 2022. He founded Eureka Labs in 2024. When he publishes an architecture pattern, it gets taken seriously. The developer community moved on it immediately.
What nobody moved on: the business owner version. Every tutorial, every implementation, every YouTube breakdown targets engineers and researchers. The question of what this means for a service firm up to 100 people running on meeting transcripts, client notes, and SOPs? Still unanswered.
How Does RAG Work, and Where Does It Fall Apart?
RAG works like this. You upload documents. When someone asks a question, the system retrieves the most relevant chunks and feeds them to the AI. The AI reads the chunks and answers.
Think of it like a filing cabinet. You ask "what did we decide about pricing for this client?" The system pulls the most relevant file. The AI reads it. It answers the question.
It works for "what" questions. It breaks on "why" questions.
"Why did we price that client at the lower tier?" requires the AI to connect the pricing call from six months ago to the conversation about their budget constraints from the intake notes to the note you wrote about their growth trajectory. RAG retrieves chunks. It doesn't connect them. It wasn't built to.
This is a limitation of the baseline RAG structure most tutorials show. More advanced versions exist. Graph RAG systems map relationships between documents instead of treating every chunk as an isolated file. They close some of these gaps, and at massive scale, a properly built RAG system can return answers dramatically faster and cheaper than any other approach. A 2025 research comparison put the gap at roughly 1,200 times faster and cheaper than loading documents directly into a context window. That's the honest case for RAG when you have a law firm's worth of documents and mostly retrieval questions.
But the RAG most people actually build or buy is not graph RAG. It's naive RAG. Chunks in silos. No relationship mapping. The accuracy on complex questions drops significantly. You end up with something that functions like an overcomplicated search bar.
Stateless AI tools fail on the questions that actually matter to a business: What does this client care about most? What's the pattern across our last five engagements? What did we learn from the mistake we made in Q3?
Those questions require synthesis across everything the business has learned. Not just what's in the document you uploaded today.
(If you've tried solving this by connecting Claude directly to Obsidian or a second brain app, here's why that approach runs into the same stateless wall.)
What Does LLM Wiki Do Differently From RAG?

The LLM Wiki is a knowledge architecture pattern where an AI agent synthesizes documents into structured, interlinked pages at the moment of ingestion. For businesses, it replaces stateless document uploads with a compounding knowledge base. Every meeting transcript, client note, and decision is organized so AI agents can reason from it immediately, not re-discover it from raw files.
Three layers:
The raw sources are the original documents: meeting transcripts, emails, contracts, notes. The AI reads them but never modifies them. They're the record.
The wiki is LLM-maintained markdown pages that synthesize and cross-reference the raw sources. Not a copy of the raw text. A structured understanding of it. "Client X: what they care about, what they've decided, what the pattern is." One page per topic, updated every time new raw sources come in.
The schema is a configuration file, basically a table of contents plus instructions, that tells the AI how the wiki is organized and how to maintain it. This is what makes the whole thing self-maintaining.
RAG makes AI answer faster. LLM Wiki makes AI answer better, because it remembers everything the business has learned, not just what's in the document you uploaded today.
The difference: RAG retrieves at query time. LLM Wiki synthesizes at ingestion. By the time you ask a question, the wiki already understands what the answer should draw from.
Why Does LLM Wiki Matter More for Service Businesses Than for Developers?
Every developer implementation of Karpathy's pattern is about code repositories, research papers, or personal notes. That makes sense. Developers have the tooling and the motivation to experiment first.
But here's what most developer implementations don't capture: service businesses run on a different kind of knowledge.
Meeting transcripts. Discovery call notes. The pricing decision you made for a client based on three different conversations. The SOP that was in your head until you tried to hand it off to someone. The pattern you've noticed across your last six engagements that you've never written down because you haven't had time.
This is the raw material for a business LLM Wiki. And it's the exact kind of knowledge that RAG handles worst, because it requires connecting dots across time, not finding the most relevant paragraph.
A developer's LLM Wiki ingests commit logs and documentation. A service business LLM Wiki ingests what the founder knows. Clients, decisions, patterns, failures, SOPs. The institutional memory that currently lives only in one person's head.
That's not just an interesting technical distinction. It's the difference between a business that runs when the founder is there and a business that runs when they're not.
How Does the Business AI Operating System Context Layer Implement This?

I've been running this pattern in my own business since November 2025. The knowledge/ directory in my Business AI Operating System workspace is exactly the four-operation cycle Karpathy describes: ingest, reflect, commit, lint-wiki.
The /ingest command takes a raw source (a meeting transcript, a research report, a decision document) and synthesizes it into a structured wiki page, connecting it to what's already in the knowledge base. Not just storing it. Synthesizing it.
The /lint-wiki command runs a monthly health check across the entire knowledge base: flags stale claims, orphan pages, contradictions between what was decided in January and what was updated in March.
My CLAUDE.md file is the schema. It tells the AI how the knowledge base is organized, what each subdirectory contains, and how to navigate it. Every session, the AI reads the schema first. It already knows where everything is.
A recent client, the founder of a whiskey brand, uses this pattern in their business. The raw inputs are investor data, ClickUp records, and transcripts from our work sessions. The wiki is his structured founder brain: client history, decisions made, the reasoning behind them, the patterns he's noticed across his market. The agent interface is the dashboard he uses to interact with it.
He can ask his AI "what was the reasoning behind our pricing decision for the distributor conversation last fall?" and get an answer that draws from three different source documents, synthesized into something coherent, not just a retrieved chunk.
This is what the Context layer of a Business AI Operating System does. It's the foundation every other layer depends on. Without compounding context, the intelligence layer is static. The automation layer is brittle. And every session starts from zero.
For how this plays out when knowledge management is the core constraint, read How AI-Powered Knowledge Management Turns Founder Expertise Into a Scalable Business Asset.
When Is RAG Still the Right Choice?
RAG wins in specific situations, and it's worth being clear about them.
If you're running a legal practice and need to search across 10,000 case files, RAG is right. The synthesis would be impractical at that volume, and the questions are mostly retrieval questions anyway. Find the precedent. Find the clause. Find the date.
Same for medical literature search, enterprise content repositories, or any situation where the document library is massive and the questions are mostly "find the document that contains X." Worth noting: the version that actually performs at that scale is graph RAG, which maps entities and relationships across documents. Not the baseline version most tools ship with. That distinction matters if you're ever evaluating a vendor or deciding whether to build.
LLM Wiki is better when you want the knowledge to compound. When the questions are about patterns, history, reasoning, and context. When the answer to "what should I do here?" requires understanding what the business has learned, not just what's in the most recent document.
For a service business up to 100 people: LLM Wiki. For a law firm needing to search case archives: graph RAG.
Neither is a magic fix. Both require you to actually feed them good raw material.
If you're not sure whether your business has this problem or what it would take to fix it, that's what the fit call is for. It's a free 45-minute diagnostic — think of it like going to the doctor. I ask questions about what's actually going on, and at the end I'll tell you honestly whether what I do is a fit. No pitch, no proposal. Just an honest read. Book a fit call.